
Dans l’économie numérique actuelle, la planification de la chaîne d’approvisionnement et la prévision exigent un accès rapide à des données précises et à des analyses performantes. SAP Integrated Business Planning (IBP) est une solution de pointe qui aide les organisations à optimiser leur supply chain et à prévoir la demande.
Mais, à mesure que le volume de données augmente et que les analyses se complexifient, le besoin d’une plateforme de données basée sur le cloud, hautement évolutive, devient crucial.
Pourquoi intégrer Snowflake avec SAP ?
Entrepôt de données avancé
Infrastructure Cloud Flexible
Avec la prise en charge des principales plateformes cloud telles que Snowflake offre une infrastructure flexible qui peut s’adapter aux exigences changeantes de l’entreprise.
Cette approche native du cloud permet un déploiement rapide, une gestion simplifiée et une réduction des charges informatiques.
Scalabilité et performance
Conçu pour gérer des volumes de données massifs avec une scalabilité pratiquement illimitée. Elle supporte des analyses à grande vitesse et un traitement simultané, garantissant ainsi que même les plus grands ensembles de données – allant des données historiques de planification aux mises à jour de prévisions en temps réel – soient traités efficacement.
Rapports améliorés et insights approfondis
En intégrant SAP IBP avec Snowflake, les organisations peuvent exploiter des outils d’analyse avancés, exécuter des requêtes complexes et générer des rapports complets. Cela permet une prise de décision basée sur les données, optimisant les stocks, améliorant la prévision de la demande et stimulant la croissance de l’entreprise.
Dans ce guide nous allons découvrir une approche complète pour intégrer SAP IBP avec Snowflake au travers de deux scénarios clés. Le premier sera la lecture de données depuis Snowflake et écriture vers SAP IBP. On abordera l’extraction des données depuis Snowflake via les SAP Open Connectors et chargement dans SAP IBP à l’aide des iFlows d’assistance et des interfaces RFC.Puis le second concernera l’écriture des données de prévision de SAP IBP vers Snowflake. Cela comprend l’extraction des données de prévision depuis SAP IBP, mise en scène via une plateforme externe (comme un bucket AWS S3) et chargement dans une table de base de données Snowflake à l’aide d’une commande COPY INTO en mode batch.
1. Comprendre les scénarios d'intégration :
Ce guide couvre deux scénarios principaux :
1.1. Lecture de données depuis Snowflake et écriture vers SAP IBP :
- Lire les données depuis Snowflake à l’aide des SAP Open Connectors.
- Transformer et charger les données dans SAP IBP via SAP Cloud Integration en utilisant des iFlows d’assistance.
1.2. Écriture des données de prévision depuis SAP IBP vers Snowflake :
- Extraire les données des indicateurs clés de prévision (par exemple, CONSDEMANDQTY) de SAP IBP.
Transformer les données, les mettre en scène de manière externe (par exemple, via un bucket AWS S3) et les charger dans une table Snowflake à l’aide d’une commande batch COPY INTO.
2. Prérequis et préparations
Avant de commencer l’intégration, assurez-vous de disposer des éléments suivants :
2.1. Environnement SAP IBP :
- Une prévision effectuée avec succès, avec des indicateurs clés disponibles (par exemple, CONSDEMANDQTY).
- Des droits administratifs et les iFlows d’assistance (inclus dans la version 2402 d’IBP) importés dans SAP Cloud Integration.
2.2. Environnement Snowflake :
- Un compte Snowflake avec une base de données, un schéma, un rôle et un utilisateur configurés correctement.
- Un utilisateur disposant des privilèges nécessaires pour lire/écrire des données (configuré avec une paire de clés RSA ou une authentification basique).
2.3. SAP Cloud Integration & Open Connectors :
- Accès à la plateforme SAP Open Connectors depuis la page d’accueil de SAP Cloud Integration.
- Une instance du connecteur Snowflake ainsi que, si vous utilisez une mise en scène externe, une instance du connecteur Amazon S3 configurée.
2.4. Mise en scène externe (optionnelle mais recommandée) :
- Un bucket AWS S3 (ou équivalent sur Google Cloud/Azure) créé via SAP BTP, avec des identifiants de service disponibles pour le connecteur.
3. Architecture globale et flux des données
L’architecture d’intégration se compose généralement des étapes suivantes :
3.1. Extraction et transformation des données :
Extraction des données depuis SAP IBP (pour les prévisions) ou depuis Snowflake. Utilisation de SAP Cloud Integration pour transformer et mapper les données dans les formats requis.
3.2. Mise en scène (pour les chargements en batch) :
Pour les gros volumes de données, celles-ci peuvent être temporairement stockées dans une zone de mise en scène externe (par exemple, un bucket AWS S3).
3.3. Chargement des données :
Chargement des données dans le système cible – soit en écrivant les données transformées dans SAP IBP à l’aide des iFlows d’assistance, soit en exécutant une commande COPY INTO pour charger les données dans une table Snowflake.
Ci-dessous, un schéma simplifié du flux global :
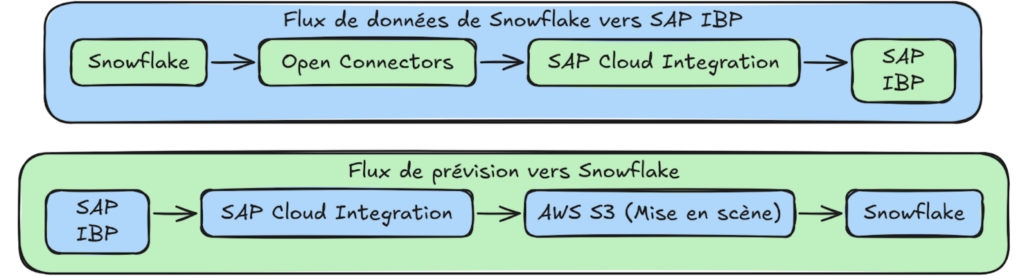
4. Configuration des Open Connectors et de SAP Cloud Integration
4.1. Tester la connectivité à Snowflake avec SNOWSQL
Avant de configurer le connecteur, vérifiez que votre utilisateur Snowflake (avec les privilèges nécessaires) peut se connecter. Si vous avez généré une paire de clés RSA comme recommandé, testez la connexion à l’aide de l’outil en ligne de commande SNOWSQL :
Cette commande établit une connexion à votre instance Snowflake, de sorte que vous pourrez utiliser des identifiants similaires dans votre instance de connecteur.
4.2. Création d’une instance de connecteur Snowflake
Avant de configurer le connecteur, vérifiez que votre utilisateur Snowflake (avec les privilèges nécessaires) peut se connecter. Si vous avez généré une paire de clés RSA comme recommandé, testez la connexion à l’aide de l’outil en ligne de commande SNOWSQL :
snowsql -a <Account identifier>-<Organization name> -u <DB user> --private-key-path <path to .p8>
Naviguez vers Discover Connectors > Instances
Cliquez sur Create Instance et recherchez le connecteur Snowflake.
Remplissez les détails requis (nom d’hôte, port, identifiants, etc.).
Un exemple de configuration pourrait être :
Nom d’hôte : ax123.snowflakecomputing.com
Port : 443
Base de données : MY_DATABASE
Schéma : PUBLIC
Rôle : SYSADMIN
Utilisateur : snowflake_user
Méthode d’authentification : RSA Key (ou mot de passe)
Clé publique RSA :
Vous pouvez saisir ces informations dans les champs correspondants lors de la création de l’instance du connecteur Snowflake sur la plateforme SAP Open Connectors. Cela permettra au connecteur de se connecter à votre compte Snowflake pour effectuer des opérations de lecture et d’écriture sur vos tables.
Une fois créée, cliquez sur le lien API Docs pour visualiser les endpoints REST. Ces endpoints encapsulent des opérations sur les tables (GET pour lire des tables, POST pour écrire des données, etc.).
4.3. Création d’un matériel de sécurité dans SAP Cloud Integration
En utilisant les informations (User, Organization, Element) disponibles dans les API Docs, créez un matériel de sécurité :
Connectez-vous à SAP Cloud Integration.
Rendez-vous dans Security Materials > Create → User Credentials.
Entrez les informations requises et déployez les identifiants.
Conservez l’URL de votre instance de connecteur Open Connector et le nom des identifiants utilisateurs pour une utilisation ultérieure dans vos iFlows.
5. Lecture des données depuis Snowflake et écriture vers SAP IBP
5.1. Lecture de données depuis Snowflake
Dans votre iFlow, configurez un adaptateur request‑response qui utilise le connecteur Snowflake. Les paramètres clés incluent :
- Resource : Le nom de la table de base de données à lire.
- Credential Name : Fourni en tant que paramètre d’en-tête (par exemple, SFDestination).
Lors de l’exécution, l’iFlow envoie une requête GET à l’instance du connecteur et renvoie des données JSON provenant de la table spécifiée. Par exemple, vous pourriez obtenir une requête cURL similaire à :
curl -X GET "https://<connector-instance-url>/tables/<tableName>" \
-H "User: <yourUser>" \
-H "Organization: <yourOrg>" \
-H "Element: <yourElement>"
Une fois que vous recevez la charge utile JSON (qui est un tableau d’objets), un script simple (en Groovy ou JavaScript) peut ajouter un attribut racine, convertir en XML, puis utiliser un mapper XSLT pour traduire les clés JSON en noms de colonnes correspondants dans SAP IBP.
5.2. Écriture de données vers SAP IBP
Les données sont écrites de manière asynchrone vers SAP IBP via des iFlows d’assistance. Le processus se déroule en trois étapes principales :
Création d’un Batch ID :
Invoquez l’iFlow d’assistance (SAP_IBP_Write_-_Create_Batches) avec la charge utile XML suivante pour générer un Batch ID. Ce Batch ID permettra de référencer les multiples requêtes POST pour écrire les indicateurs clés :
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<IBPWriteBatches>
<IBPWriteBatch Key="ConsensusDemand" Name="Snowflake Planning Data"
Destination="${header.IBPDestination}"
Command="INSERT_UPDATE"
PlanningArea="${header.IBPPlanningArea}"
PlanningAreaVersion=""/>
</IBPWriteBatches>
Écriture des indicateurs clés par batch :
Utilisez le Batch ID généré pour envoyer les données des indicateurs clés en plusieurs lots. La charge utile XML ci-dessous illustre comment les lignes d’une table Snowflake (mappées aux colonnes d’indicateurs clés de SAP IBP) sont traitées :
<multimap:Messages>
<multimap:Message1>
<IBPWriteKeyFigures
FieldList="{list of fields}"
BatchKey="{IBPGuid}"
FileName="SnowflakeDataLoad">
<!-- Ici, chaque objet JSON d'une ligne de Snowflake est itéré -->
<xsl:for-each select="$InputPayload/Snowflake/values">
<item>
<PRDID><xsl:value-of select="./PRODUCT"/></PRDID>
<LOCID><xsl:value-of select="./LOCATION"/></LOCID>
<CUSTID><xsl:value-of select="./CUSTOMER"/></LOCID>
<CONSENSUSDEMANDQTY><xsl:value-of select="./CONSDEMAND"/></CONSENSUSDEMANDQTY>
<!-- Exemple : 2024-02-20T00:00:00 -->
<KEYFIGUREDATE><xsl:value-of select="./CONSDEMAND"/></KEYFIGUREDATE>
</item>
</xsl:for-each>
</IBPWriteKeyFigures>
</multimap:Message1>
</multimap:Messages>
Post-traitement :
Une fois toutes les requêtes POST envoyées, l’iFlow d’assistance (SAP_IBP_Write_-_Process_Posted_Data) gère le post-traitement final. Une réponse XML réussie pourrait ressembler à :
<Files>
<File Count="2" Name="SnowflakeDataLoad" PlanningArea="XPACNT2305" Status="PROCESSED" TypeOfData="Key Figure Data"/>
</Files>
<Messages/>
<ScheduleResponse>
<Status>OK</Status>
<Messages/>
</ScheduleResponse>
Cela confirme que le fichier SnowflakeDataLoad a été traité avec succès dans le backend IBP.
6. Écriture des données de prévisions depuis SAP IBP vers Snowflake
Cette section explique comment extraire les données de prévision depuis SAP IBP, les mettre en scène de manière externe, et les charger dans une table de base de données Snowflake.
6.1. Préparation de l’extraction des données de SAP IBP
Avant l’extraction, assurez-vous qu’une prévision a été effectuée dans SAP IBP et que votre indicateur clé (par exemple, CONSDEMANDQTY) est disponible. Ensuite, configurez le scénario de communication IBP (généralement SAP_COM_0931) dans votre système SAP IBP.
Lecture des données depuis SAP IBP
Le processus est divisé en deux étapes en utilisant des iFlows d’assistance :
Initialisation :
Lancez une requête de sélection à l’aide de la charge utile XML suivante :
<IBPReads>
<IBPRead Key="${header.IBPQueryKey1}"
Destination="${header.IBPDestination}"
PackageSizeInRows="${header.IBPPackageSizeInRows}"
Select="${header.IBPQuerySelect}"
OrderBy="${header.IBPQueryOrderBy}"
Filter="${header.IBPQueryFilterString}"
TypeOfData="${header.IBPQueryTypeOfData}"
TimeAggregationLevel="2"/>
</IBPReads>
Récupération des données :
Une fois la requête initialisée (l’iFlow d’assistance effectuera une boucle jusqu’à ce qu’il renvoie un statut FETCH_DATA), utilisez cette charge utile pour récupérer les données par lots :
<IBPRead>
<xsl:attribute name="Key"><xsl:value-of select="$IBPQueryKey1"/></xsl:attribute>
<xsl:attribute name="Offset"><xsl:value-of select="$IBPQueryOffset1"/></xsl:attribute>
<xsl:attribute name="PackageSizeInRows"><xsl:value-of select="$IBPPackageSizeInRows"/></xsl:attribute>
<xsl:attribute name="ParallelThread"><xsl:value-of select="$IBPQueryParallelThread"/></xsl:attribute>
</IBPRead>
La réponse – initialement en XML – est convertie en JSON (à l’aide d’un convertisseur XML vers JSON), puis un script Groovy est utilisé pour préparer les données en vue de la mise en scène.
Les données de prévision sont stockées sous forme de fichier JSON dans un bucket AWS S3. Utilisez la fonction Groovy suivante pour emballer les données dans un message MIME multipart :
// Data payload from the previous step
JSONArray valueJSONArray = input.get("AWSPayload");
def prettyBody = valueJSONArray.toString() as String;
def bytes = prettyBody.getBytes();
// Create a new Multipart MIME envelope
MimeBodyPart bodyPart = new MimeBodyPart()
// Data source envelope with input as bytes
ByteArrayDataSource dataSource = new ByteArrayDataSource(bytes, 'application/json')
// Data handler envelope with the data source
DataHandler byteDataHandler = new DataHandler(dataSource)
bodyPart.setDataHandler(byteDataHandler)
// Set file name and type for the data
String fileName = input.AWSFileName
bodyPart.setFileName(fileName)
String fileType = input.AWSFileType
bodyPart.setDisposition('form-data; name="file"')
bodyPart.setHeader("Content-Type", fileType)
MimeMultipart multipart = new MimeMultipart()
// Add body parts to the multipart
multipart.addBodyPart(bodyPart)
// Convert the multipart message to a byte array output stream
ByteArrayOutputStream outputStream = new ByteArrayOutputStream()
multipart.writeTo(outputStream)
message.setBody(outputStream)
// Set the boundary for the multipart message
String boundary = (new ContentType(multipart.contentType)).getParameter('boundary')
message.setHeader('Content-Type', "multipart/form-data; boundary=${boundary}")
// Set additional headers (using a helper method)
message = setHeader(message);
return message;
<ScheduleResponse>
<Status>OK</Status>
<Messages/>
</ScheduleResponse>
6.2. Préparation de l’extraction des données de SAP IBP
Dans la méthode d’assistance setHeader, vous ajoutez les détails d’authentification récupérés depuis votre instance Open Connector :
def Message setHeader(Message message) {
def properties = message.getProperties();
String user = properties.get("OCUser") as String;
String org = properties.get("OCOrg") as String;
String element = properties.get("OCElement") as String;
message.setHeader("Authorization", "User " + user + ", Organization " + org + ", Element " + element);
return message;
}
6.3. Chargement des données dans Snowflake
Une fois le fichier JSON stocké dans le bucket S3, l’étape suivante consiste à le charger dans une table Snowflake (par exemple, IBPFORECAST). Cela se fait en exécutant une commande SQL via le connecteur Snowflake.
Exemple de commande SQL
Si vous devez générer dynamiquement la commande SQL, vous pouvez utiliser un script Groovy comme le suivant :
def Message handleRequestToLoadSnowflake(Message message) {
def body = message.getBody(java.io.Reader);
def input = new JsonSlurper().parse(body);
// Set properties for Open Connectors and Snowflake
message.setProperty("OCURL", input.OCURL);
message.setProperty("SFTarget", input.SFTarget);
message.setProperty("SFStaging", input.SFStaging);
message.setProperty("SFDestination", input.SFDestination);
String sqlScript = "COPY INTO " + input.SFTarget +
" FROM " + input.SFStaging +
" FILE_FORMAT = ( TYPE=JSON, STRIP_OUTER_ARRAY=TRUE, REPLACE_INVALID_CHARACTERS=TRUE, DATE_FORMAT=AUTO, TIME_FORMAT=AUTO, TIMESTAMP_FORMAT=AUTO ) " +
"MATCH_BY_COLUMN_NAME=CASE_INSENSITIVE ON_ERROR=CONTINUE";
JSONObject requestObject = new JSONObject();
requestObject.put("script", sqlScript);
def prettyBody = requestObject.toString() as String;
message.setBody(prettyBody);
return message;
}
Lors de l’exécution, Snowflake renvoie une réponse JSON similaire à :
[
{
"rows_loaded": 10000,
"errors_seen": 0,
"file": "s3://<S3 bucket name>/data/sap/forecast.json",
"error_limit": 10000,
"rows_parsed": 10000,
"status": "LOADED"
}
]
Cela confirme que 10 000 lignes ont été chargées avec succès dans la table IBPFORECAST.
6. Écriture des données de prévisions depuis SAP IBP vers Snowflake
Cette section explique comment extraire les données de prévision depuis SAP IBP, les mettre en scène de manière externe, et les charger dans une table de base de données Snowflake.
6.1. Préparation de l’extraction des données de SAP IBP
Avant l’extraction, assurez-vous qu’une prévision a été effectuée dans SAP IBP et que votre indicateur clé (par exemple, CONSDEMANDQTY) est disponible. Ensuite, configurez le scénario de communication IBP (généralement SAP_COM_0931) dans votre système SAP IBP.
Lecture des données depuis SAP IBP
Le processus est divisé en deux étapes en utilisant des iFlows d’assistance :
Initialisation :
Lancez une requête de sélection à l’aide de la charge utile XML suivante :
<IBPReads>
<IBPRead Key="${header.IBPQueryKey1}"
Destination="${header.IBPDestination}"
PackageSizeInRows="${header.IBPPackageSizeInRows}"
Select="${header.IBPQuerySelect}"
OrderBy="${header.IBPQueryOrderBy}"
Filter="${header.IBPQueryFilterString}"
TypeOfData="${header.IBPQueryTypeOfData}"
TimeAggregationLevel="2"/>
</IBPReads>
Récupération des données :
Une fois la requête initialisée (l’iFlow d’assistance effectuera une boucle jusqu’à ce qu’il renvoie un statut FETCH_DATA), utilisez cette charge utile pour récupérer les données par lots :
<IBPRead>
<xsl:attribute name="Key"><xsl:value-of select="$IBPQueryKey1"/></xsl:attribute>
<xsl:attribute name="Offset"><xsl:value-of select="$IBPQueryOffset1"/></xsl:attribute>
<xsl:attribute name="PackageSizeInRows"><xsl:value-of select="$IBPPackageSizeInRows"/></xsl:attribute>
<xsl:attribute name="ParallelThread"><xsl:value-of select="$IBPQueryParallelThread"/></xsl:attribute>
</IBPRead>
La réponse – initialement en XML – est convertie en JSON (à l’aide d’un convertisseur XML vers JSON), puis un script Groovy est utilisé pour préparer les données en vue de la mise en scène.
Les données de prévision sont stockées sous forme de fichier JSON dans un bucket AWS S3. Utilisez la fonction Groovy suivante pour emballer les données dans un message MIME multipart :
// Data payload from the previous step
JSONArray valueJSONArray = input.get("AWSPayload");
def prettyBody = valueJSONArray.toString() as String;
def bytes = prettyBody.getBytes();
// Create a new Multipart MIME envelope
MimeBodyPart bodyPart = new MimeBodyPart()
// Data source envelope with input as bytes
ByteArrayDataSource dataSource = new ByteArrayDataSource(bytes, 'application/json')
// Data handler envelope with the data source
DataHandler byteDataHandler = new DataHandler(dataSource)
bodyPart.setDataHandler(byteDataHandler)
// Set file name and type for the data
String fileName = input.AWSFileName
bodyPart.setFileName(fileName)
String fileType = input.AWSFileType
bodyPart.setDisposition('form-data; name="file"')
bodyPart.setHeader("Content-Type", fileType)
MimeMultipart multipart = new MimeMultipart()
// Add body parts to the multipart
multipart.addBodyPart(bodyPart)
// Convert the multipart message to a byte array output stream
ByteArrayOutputStream outputStream = new ByteArrayOutputStream()
multipart.writeTo(outputStream)
message.setBody(outputStream)
// Set the boundary for the multipart message
String boundary = (new ContentType(multipart.contentType)).getParameter('boundary')
message.setHeader('Content-Type', "multipart/form-data; boundary=${boundary}")
// Set additional headers (using a helper method)
message = setHeader(message);
return message;
<ScheduleResponse>
<Status>OK</Status>
<Messages/>
</ScheduleResponse>
6.2. Préparation de l’extraction des données de SAP IBP
Dans la méthode d’assistance setHeader, vous ajoutez les détails d’authentification récupérés depuis votre instance Open Connector :
def Message setHeader(Message message) {
def properties = message.getProperties();
String user = properties.get("OCUser") as String;
String org = properties.get("OCOrg") as String;
String element = properties.get("OCElement") as String;
message.setHeader("Authorization", "User " + user + ", Organization " + org + ", Element " + element);
return message;
}
6.3. Chargement des données dans Snowflake
Une fois le fichier JSON stocké dans le bucket S3, l’étape suivante consiste à le charger dans une table Snowflake (par exemple, IBPFORECAST). Cela se fait en exécutant une commande SQL via le connecteur Snowflake.
Exemple de commande SQL
Si vous devez générer dynamiquement la commande SQL, vous pouvez utiliser un script Groovy comme le suivant :
def Message handleRequestToLoadSnowflake(Message message) {
def body = message.getBody(java.io.Reader);
def input = new JsonSlurper().parse(body);
// Set properties for Open Connectors and Snowflake
message.setProperty("OCURL", input.OCURL);
message.setProperty("SFTarget", input.SFTarget);
message.setProperty("SFStaging", input.SFStaging);
message.setProperty("SFDestination", input.SFDestination);
String sqlScript = "COPY INTO " + input.SFTarget +
" FROM " + input.SFStaging +
" FILE_FORMAT = ( TYPE=JSON, STRIP_OUTER_ARRAY=TRUE, REPLACE_INVALID_CHARACTERS=TRUE, DATE_FORMAT=AUTO, TIME_FORMAT=AUTO, TIMESTAMP_FORMAT=AUTO ) " +
"MATCH_BY_COLUMN_NAME=CASE_INSENSITIVE ON_ERROR=CONTINUE";
JSONObject requestObject = new JSONObject();
requestObject.put("script", sqlScript);
def prettyBody = requestObject.toString() as String;
message.setBody(prettyBody);
return message;
}
Lors de l'exécution, Snowflake renvoie une réponse JSON similaire à :
[
{
"rows_loaded": 10000,
"errors_seen": 0,
"file": "s3://<S3 bucket name>/data/sap/forecast.json",
"error_limit": 10000,
"rows_parsed": 10000,
"status": "LOADED"
}
]
Cela confirme que 10 000 lignes ont été chargées avec succès dans la table IBPFORECAST.
7. Bonnes pratiques et considérations
Vérification de la qualité des données :
Validez les comptes, les types de données et le contenu avant et après les transformations.Gestion des erreurs :
Mettez en place une gestion robuste des erreurs et une journalisation dans vos iFlows. Surveillez les statuts renvoyés par SAP IBP et Snowflake.Optimisation des performances :
Effectuez les chargements par lots lorsque c’est possible.
Optimisez la table Snowflake en utilisant des clés de clustering si nécessaire.
Utilisez des chargements incrémentiels pour réduire la charge.
Sécurité :
Sécurisez les données en transit grâce au chiffrement et gérez les identifiants de manière sécurisée (tant pour Snowflake que pour les Open Connectors).
Surveillance : Utilisez le tableau de bord de surveillance de SAP Cloud Integration et l’historique des requêtes de Snowflake pour suivre les flux de données et résoudre les problèmes. En suivant ce guide détaillé, vous pourrez intégrer avec succès SAP IBP avec Snowflake afin de permettre un flux de données bidirectionnel. Que vous lisiez des données depuis Snowflake pour améliorer votre planification de la supply chain dans SAP IBP ou que vous écriviez des données de prévision de SAP IBP vers Snowflake pour des analyses avancées.