
Dans le paysage technologique actuel, l’analyse de données non structurées, telles que les documents PDF, est devenue cruciale pour les entreprises. Cependant, traiter ces documents à grande échelle présente des défis significatifs. Mais Snowflake a introduit de nouvelles fonctionnalités pour faciliter ce processus, notamment le type de données VECTOR et les fonctions de similarité vectorielle.
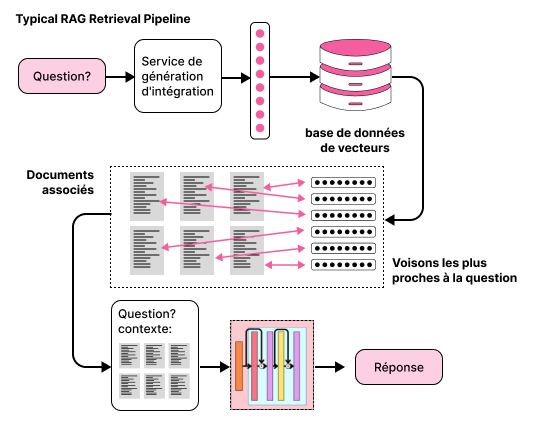
Nouvelles Fonctionnalités de Snowflake
En mai 2024, Snowflake a annoncé la préversion de son type de données VECTOR, accompagné de fonctions de similarité vectorielle. Ces outils permettent de représenter des données complexes, comme du texte non structuré, sous forme de vecteurs numériques. Cette représentation facilite la recherche sémantique et le traitement de données non structurées directement au sein de Snowflake.
Les principales fonctions de similarité vectorielle introduites incluent :
– VECTOR_INNER_PRODUCT : calcule le produit scalaire entre deux vecteurs, mesurant leur similarité en fonction de leur projection mutuelle.
– VECTOR_L1_DISTANCE et VECTOR_L2_DISTANCE : mesure la distance entre deux vecteurs selon les normes L1 et L2, respectivement.
– VECTOR_COSINE_SIMILARITY : évalue la similarité entre deux vecteurs en calculant le cosinus de l’angle entre eux.
Ces fonctionnalités ouvrent la voie à des applications avancées, telles que la recherche sémantique et l’intégration avec des modèles de langage pour des tâches de génération augmentée par récupération (RAG).
Défis du traitement de grandes Bases de Données PDF
Malgré ces avancées, le traitement de vastes collections de documents PDF reste complexe.
Les défis incluent :
– Volume de données : les bases de données volumineuses peuvent contenir des millions de documents, rendant leur gestion et leur analyse ardues.
– Extraction de contenu : extraire des informations précises de documents PDF hétérogènes nécessite des outils sophistiqués capables de gérer diverses mises en page et formats ( et parfois, les pdf, c’est juste des pages et des pages d’images, alors ça doit passer par un processus OCR au lieu d’extraction du texte) .
– Performances : maintenir des performances constantes lors de l’interrogation de grandes bases de données est un défi majeur, surtout lorsque les ressources sont limitées.
Solutions proposées :
Pour surmonter ces obstacles, l’utilisation des nouvelles fonctionnalités de Snowflake offre des avantages significatifs :
– Stockage Efficace : le type de données VECTOR permet de stocker des représentations vectorielles des documents, facilitant leur manipulation et leur analyse.
– Recherche Sémantique : les fonctions de similarité vectorielle permettent d’effectuer des recherches basées sur le contenu sémantique des documents, améliorant ainsi la pertinence des résultats.
– Intégration Simplifiée : L’intégration avec des pipelines RAG permet d’interagir efficacement avec des modèles de langage pour extraire des informations pertinentes des documents PDF.
En adoptant ces solutions, les entreprises peuvent améliorer leur capacité à traiter et analyser de grandes collections de documents PDF, transformant ainsi des données non structurées en informations exploitables.
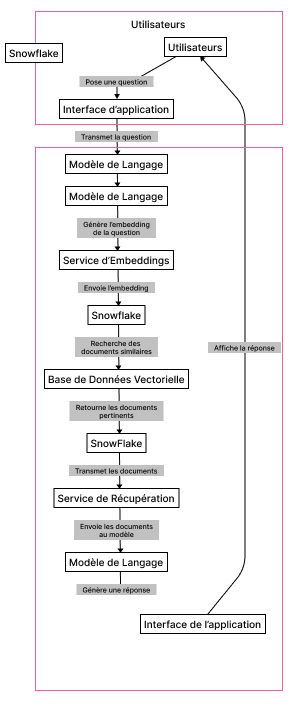
Dans cet article, nous allons explorer comment utiliser Snowflake pour stocker et interroger des embeddings vectoriels, en l’intégrant avec LangChain pour construire une application simple de RAG (Retrieval-Augmented Generation) permettant de poser des questions et d’obtenir des réponses à partir d’un document PDF.
1. Configuration de l'environnement
Commencez par installer les bibliothèques nécessaires :
pip install langchain
pip install langchain-community
pip install langchain-openai
pip install azure-identity
pip install openai
pip install snowflake-connector-python
pip install pyarrow
pip install pandas
pip install pypdf
2. Création de la table Snowflake pour le stockage des vecteurs
Ensuite, nous allons créer une table dans Snowflake pour stocker nos embeddings en utilisant le type de données VECTOR. Le nombre de dimensions dans la définition de la colonne vectorielle dépendra du modèle que vous utilisez pour les embeddings. Comme nous utiliserons le modèle ada-2 d’OpenAI (text-embedding-ada-002), nous définirons notre colonne vectorielle avec 1536 dimensions.
CREATE OR REPLACE TABLE PDF_EMB (
id INT IDENTITY,
content VARCHAR,
content_vector VECTOR(FLOAT, 1536),
meta VARCHAR,
link VARCHAR,
create_at DATE
);
3. Chargement et découpage des documents
Nous allons maintenant charger un document PDF et le diviser en segments gérables. Cette fonction utilise le PyPDFLoader de LangChain et la bibliothèque PyPdf pour charger et diviser le PDF en documents plus petits :
def load_and_split_pdf(file_path):
loader = PyPDFLoader(file_path)
docs = loader.load_and_split()
return docs
4. Création des embeddings
Pour créer des embeddings pour nos segments de document, nous utiliserons le modèle text-embedding-ada-002 d’OpenAI hébergé sur Azure. Cette fonction utilise LangChain pour créer des représentations vectorielles de notre texte.
def create_embedding(doc_text):
embeddings = AzureOpenAIEmbeddings(
model=EMBEDDING_MODEL,
chunk_size=10000,
openai_api_key=openai.api_key,
azure_endpoint=openai.api_base
)
embedding = embeddings.embed_query(doc_text)
return embedding
5. Stockage des embeddings dans Snowflake
Stockons maintenant ces embeddings dans Snowflake. Cette fonction parcourt nos documents, crée des embeddings et les stocke dans Snowflake en utilisant du SQL standard. Notez l’utilisation du type de données VECTOR dans Snowflake, essentiel pour des recherches de similarité efficaces.
# Parcourir les documents et les envoyer à Snowflake
for doc in docs:
print("Envoi du document à Snowflake : " + str(doc.metadata))
# Construire les champs link et meta
content = doc.page_content
link = doc.metadata['source']
meta = {
'source': link,
'page': doc.metadata['page']
}
# Obtenir l'embedding pour le texte
embedding = create_embedding(content)
# Sauvegarder dans Snowflake
base_sql = f"""
INSERT INTO PDF_EMB
(content, content_vector, meta, link, create_at)
SELECT
'{content}', {embedding}::VECTOR(FLOAT, 1536), '{meta}', '{link}', CURRENT_DATE();
"""
# Exécuter la requête SQL pour insérer les données
# Assurez-vous d'avoir une connexion établie à Snowflake
cursor.execute(base_sql)
Cette approche démontre comment vous pouvez utiliser les fonctionnalités de base de Snowflake pour créer une solution robuste de base de données vectorielle sans dépendre de services d’IA supplémentaires. De plus, elle vous permet d’utiliser SQL pour effectuer facilement des filtrages supplémentaires sur les métadonnées et vous offre la possibilité de créer facilement des applications d’IA générative sur vos données existantes dans Snowflake.