
Une brique fondatrice des architectures modernes
À l’ère du cloud computing, des microservices et des systèmes fortement découplés, le besoin de traiter, transporter et réagir à des événements en temps réel est devenu central dans les systèmes d’information.
Dans ce contexte, Apache Kafka s’est imposé comme un outil incontournable. Bien plus qu’un simple système de messagerie, Kafka est aujourd’hui considéré comme la colonne vertébrale des architectures événementielles modernes. Cette reconnaissance repose principalement sur trois piliers :
- Le modèle Pub/Sub (publish/subscribe)
- Le stockage persistant des messages
- Le traitement en temps réel
Les composants fondamentaux de Kafka
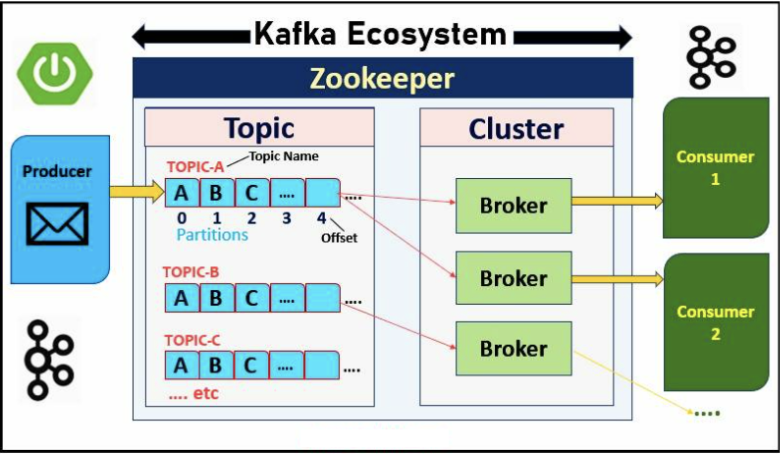
Afin de bien comprendre le fonctionnement de Kafka, il est essentiel de saisir le rôle de ses composants clés. En effet, chacun d’eux joue une fonction bien définie dans l’acheminement, le stockage et la consommation des messages au sein de l’écosystème Kafka.
 Producteurs (Producers)
Producteurs (Producers)
Concrètement, les producteurs sont les applications ou services qui génèrent des messages et les transmettent à Kafka. Ces messages sont ensuite publiés dans des topics, qui jouent le rôle de canaux de diffusion.
Autrement dit, le producteur ne se préoccupe pas de savoir qui consommera le message : il se contente de transmettre l’information au bon endroit, au bon moment.
Un producteur Kafka peut choisir dynamiquement :
- Le topic cible.
- La clé du message (qui peut influencer la partition choisie).
- Le contenu du message (payload).
Kafka se charge ensuite de distribuer le message dans une partition du topic. En utilisant une clé, on peut garantir que des messages similaires vont dans la même partition — ce qui est crucial pour certains traitements ordonnés.
 Topics
Topics
Un topic représente un canal logique de communication dans Kafka, comparable à une file de messages ou à une table de logs. C’est au sein de ces topics que les producteurs publient leurs messages, tandis que les consommateurs viennent les lire.
Par ailleurs, chaque topic est divisé en une ou plusieurs partitions, qui constituent des unités de stockage et de parallélisation.
Plus précisément, une partition est un journal ordonné de type append-only (écriture uniquement en fin), dans lequel chaque message se voit attribuer un offset unique, c’est-à-dire un identifiant propre au message dans la partition.
Grâce à ce mécanisme, Kafka peut scaler horizontalement : plusieurs producteurs ou consommateurs peuvent ainsi travailler simultanément sur différentes partitions.
Enfin, Kafka garantit l’ordre des messages à l’intérieur d’une même partition, mais pas entre plusieurs partitions, ce qui constitue un compromis entre performance et ordre strict.
 Consommateurs (Consumers)
Consommateurs (Consumers)
Les consommateurs sont les applications chargées de lire les messages stockés dans les topics. Kafka adopte ici un modèle de type pull : autrement dit, c’est le consommateur qui vient chercher les messages à son propre rythme, plutôt que de les recevoir automatiquement dès leur publication.
Par ailleurs, les consommateurs peuvent être regroupés en groupes de consommateurs. Ce mécanisme offre plusieurs avantages majeurs :
Il permet de répartir automatiquement les partitions entre les membres du groupe, assurant ainsi un équilibrage de charge.
Il garantit que chaque message est traité une seule fois, par un seul membre du groupe.
Il favorise une scalabilité horizontale, en facilitant l’ajout de nouveaux consommateurs pour gérer un volume croissant de messages.
En complément, chaque consommateur est responsable de la gestion de son propre offset (c’est-à-dire sa position dans la partition).
Ce fonctionnement offre une grande souplesse, notamment en permettant la reprise après une panne, la relecture de messages, ou encore un traitement personnalisé selon les besoins de l’application.
 Brokers
Brokers
Un broker Kafka est un serveur chargé de stocker les données et de traiter les requêtes en provenance des producteurs et des consommateurs. Dans une architecture distribuée, plusieurs brokers sont regroupés au sein d’un cluster Kafka, où ils collaborent pour assurer la performance et la résilience du système.
Plus précisément, les brokers ont pour missions de :
- Héberger les partitions associées à différents topics,
- Répliquer les données afin de garantir une tolérance aux pannes,
- Distribuer les messages et gérer leur répartition en fonction de la charge.
Par ailleurs, chaque partition est hébergée sur un ou plusieurs brokers :
- Une partition principale, appelée leader, est responsable des opérations de lecture et d’écriture ;
- Les autres brokers hébergent des répliques secondaires, qui sont synchronisées automatiquement avec la partition leader.
Grâce à ce mécanisme de réplication, Kafka assure une haute disponibilité : même en cas de panne d’un broker, les données restent accessibles et le système peut continuer à fonctionner sans interruption.
Après la théorie, place à l’action.
Désormais, nous allons mettre en œuvre un exemple fonctionnel, dans lequel un producteur Kafka envoie des messages à un consommateur, le tout développé en Java avec Spring Boot, puis exécuté localement via Docker Compose.
Stack technique utilisée
Pour cet exemple, nous utiliserons les outils suivants :
- Spring Boot : pour créer rapidement une application Java prête à l’emploi.
- Spring for Apache Kafka (spring-kafka) : module d’intégration Kafka pour Spring.
- Apache Kafka + Zookeeper : les deux sont déployés localement via Docker, grâce aux images officielles de Confluent.
Exemple simple : Producteur et Consommateur
application.yml (Spring Boot)
Dans ce fichier, nous définissons les paramètres de connexion de Kafka côté consommateur :
@KafkaListener permet d’abonner automatiquement cette méthode au topic demo-topic.
Le message est reçu de manière asynchrone et affiché dans la console.
 Docker Compose pour lancer Kafka localement
Docker Compose pour lancer Kafka localement
Voici un fichier docker-compose.yml minimal pour lancer rapidement un environnement Kafka local :